4 Frequency
4.1 Common and uncommon vowels
In order to illustrate some basic frequency effects (as in count not pitch), we had a little experiment in class today with German vowels.
Let’s consider a subset of the German monophthongs with relatively consistent phonetic spellings. We’re taking orthography as an approximation for pronunciation here.
- Experimental task:
- Within one minute, find as many words as you can that begin with either one of the characters.
| Grapheme | Token count (LCC6) | Type count | This course | Average across courses |
|---|---|---|---|---|
| 〈a〉 | 376,588 | 22915 | 31 | 22.3 |
| 〈e〉 | 343,636 | 16407 | – | – |
| 〈i〉 | 258,792 | 6614 | 31 | 15.2 |
| 〈u〉 | 191,164 | 8122 | 22 | 12.0 |
| 〈o〉 | 47,160 | 5062 | 25 | 11.8 |
| 〈ü〉 | 22,095 | 872 | 11 | 11.2 |
| 〈ö〉 | 2,209 | 100 | 4 | 6.3 |
# CQP query example, words beginning with "a", and ignore case:
LCC-DEU-NEWS-2010
a="a.+" %c
# for token counts
size a
# for (case-insensitive) type counts, using external program "wc" to count lines
count a by word %c > "| wc -l"The expected outcome: People find most words with a, then i and u, and much less with ü and ö. The groups brainstorming for more common vowels had many more distinct words to choose from, which they are also more likely to have encountered more often. If you were to ask how difficult learners of German perceive the pronunciation of each of these vowels, you would see a correlation with the frequency with which those vowels appear in corpus data.
Furthermore, we can observe that front rounded vowels are rare across language (Maddieson 2013). But why are those vowels so much rarer in the first place?
There are three possibilities:
- There is a mistake in the approach to counting.
- It is coincidence
- There is something categorically different about ü and ö
Let’s assume the latter is the case. What ü and ö have in common is that they are front rounded vowels. In fact, we have a pretty good idea about why they are special. In a nutshell: the frequency make-up (in the sense of pitch) of front rounded vowels is not as distinctive as that of other vowels. [a, i, u] are maximally distinct from each other so (almost) all language make a distinction between them. [i] and [e] are more similar in sound yet still much more distinct than [i] and [y]. It is much more common to see a language make a distinction between the former than the latter. The exact cross-linguistic patterns and the interesting bio-physical reasons are far outside the scope of this course, unfortunately. The important conclusion is that we found an interesting correlation with the help of corpus data that we could corroborate with other pieces of data, and that ultimately leads us to a fundamental property of language.
4.2 Confounding variables
There is a fundamental flaw in our operationalization of the concept of “vowel”. We measured vowel counts with orthographic characters. Here is a non-exhaustive list of what could lead to a systematic skew in our data
- e regularly represents at least 3 different vowel phonemes: ə, e, ɛ
- there is considerable overlap to the grapheme ä
- the schwa realization ə of the grapheme e cannot occur at the onset of a word
- there are common prefixes (an, un, über, ), that cause many different types
- e, i, a, and u occur in diphthongs which are phonologically different
- i, a, and u might represent different monophthongs (especially in loan words)
- ö and ü are sometimes transliterated with oe and ue
There are always many factors that could skew your data in one direction or another. In this case, the observed pattern is probably amplified by the variables above. A better operationalization would involve phonetic annotation so that we count the right thing. Ideally, you would control for those confounding variables, and if you can’t, judge the potential influence. One of the guiding principles in research is: always try to prove yourself wrong.
4.3 Different types of frequency
Most of the data we have encountered was count data. Even though a count is one of the simplest measures possible, there are many ways you will encounter it.
- Absolute frequency
- Basic measure
- Should always be reported since everything else is based on it
- Sometimes hard to visualize
- Hard to interpret across different sample or category sizes
- Relative frequency
- Absolute frequency divided by all occurrences within a category
- Either between 0 and 1 or 0% and 100%
- Makes it possible to compare between different sized samples or sub-categories
- extremely low relative frequency is sometimes reported as normalized frequency, e.g. 1 per Million == 0.000001 == 0.0001%
- Log frequency
- logarithmic transformation of absolute frequencies
- Most commonly base 10, i.e. 1 to 10 is the same distance as 10 to 100, 100 to 1,000, etc.
- Uses:
- Visualize heavily skewed data
- Make exponential data linear (e.g. word counts)
- Approximate human perception of quantities
Log scale presentation of frequencies is common with count data for two reasons. Firstly, most words/phrases/structures have few types that are extremely frequent and many types that are extremely infrequent (Zipf’s law). This makes visualization or generally reasoning about quantity differences difficult.
Secondly, human perception is much well tuned to relative quantities than absolute ones (Weber-Fechner law).
Weber-Fechner Law (cf. Kromer 2003)
- human perception is based on ratios
- absolute differences become exponentially less informative
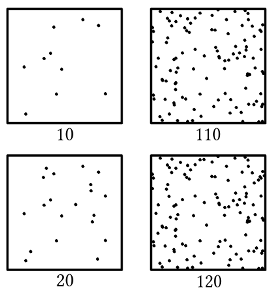
It is much easier to tell the difference between the 10 dots and 20 dots than between the 110 and 120 dots even though the absolute difference is exactly the same. Similar effects can be observed for acoustic frequencies (pitch is essentially also count data, that’s why it’s also measured in frequency), brightness, memory, language learning, etc. The opposite of exponentiation is the taking the logarithm, therefore log-scales are used a lot in information theory (remember Mutual Information) and linguistics.
4.4 Homework
- Watch §3 through §4 from this CQP tutorial: CQP Playlist
- Make sure you have the CQP cheat sheet downloaded and ready for the next weeks: CQP Cheat Sheet
Experiment with the commands discussed there. If you watch the first chapters from the tutorial, note that the setup method described there no longer works.
4.5 Tip of the day
Today, just some reflections on a general mindset I think people can profit from:
No matter your skill level: re-read and re-watch basics over and over.
Instructors have a different perspective and very often explain aspects that seem important at their own skill level. Sometimes there are realizations of the type: “I should have known that when I started”, or, “now that I know x, y becomes so much clearer”. Very often, however, this is a fallacy, and that type of information is not yet useful to a beginner at all. Therefore, most introductory materials have a lot to offer to advanced learners as they offer insights into the thinking of a fellow-learner. I, personally, still go over introductory materials again and again, be it in linguistics, statistics, programming or whatever I need in my day-to-day job. People who stop with that, I believe, lose track of what’s important really quickly. They also might not even be aware that they don’t have sufficient understanding of some of the ‘basics’ in their field.
So re-read, re-watch, re-visit. If you think, you know your way around in your field of interest, go back and reflect on it. There will be aspects you have overlooked. And, if you feel like your still a novice, it’ll help anyway. Worst case: you have the same joy of discovering the facts and feelings that lead you to your field in the first place. It’s never a waste of time. :)
Which leads me to the practical conclusion: if you end up struggling to find something in linguistics that is worth writing about in your term paper, return to the beginnings, skim through introductory videos, textbooks, slides, etc. If you’re not yet brimming with ideas and vibrating with an urge to find out more about language, go back to the basics. Maybe you discover things you didn’t see when there was an exam in your neck.