10 Productivity
When it comes to derivational affixes, there are 3 concepts that become very important when you work with data.
- Analyzability
- Semantic transparency
- Productivity
The first aspect, is related to the question of whether a word is complex or not. There are monomorphemic (simple) and polymorphemic (complex) words based on whether you can break them up into component parts. This is straightforward in most cases:
- {Analyz}-{abil}-{ity}
- {Productiv}-{ity}
These two words are clearly composed of smaller meaningful units. Note that there is a lot of spelling variation at morpheme boundaries and there is also allomporphy. Don’t confuse the two. productive is missing its final 〈e〉 when it occurs with a suffix, but the phonological form changes. This is a purely orthographic convention. The change in stress from productive to productivity, however, does cause a change in the phonetic form: /pɹədˈʌktɪv/ → /pɹədəktˈɪv-/. Likewise, the change of the suffix {able} from /-ɪbɫ/ in analyzable to /-ɪˈbɪl-/ can be considered allomorphy.
Another dimension of complexity comes into play when encounter words in your data for which it isn’t even clear whether they are complex or not. Some might seem complex, but require meta-linguistic knowledge, i.e. explicit, learned knowledge about the language. Common cases are loanwords like: poltergeist, schizophrenia, statistics, To a German speaker poltergeist clearly seems polymorphemic because it is a compound in German. This knowledge, however, needs to be learned explicitly by a native speaker of English, because neither component is used on its own in English. schizophrenia is a similar case. You can analyze the component parts academically by looking up the etymological origin. Within the English language without explicit knowledge of Latin and Greek. statistics is trickier. There might be a degree of analyzability here because the suffix -ics is common enough in English, especially for academic disciplines. It is still different from regular derived words in that the root alone doesn’t really carry a conventional meaning, at least one conventional in English. The root in statistics can be considered semantically opaque, which is the opposite of semantically transparent.
Now let’s consider the following three examples:
- ceiling
- building (N)
- interesting
All three words have a very recognizable English -ing suffix. In that sense, they are clearly analyzable as polymorphemic. That means in a native speaker of English the different components might trigger multiple associations. They are still problematic examples if you are interested in derivations with -ing. ceiling has a similar problem to statistics because the root is not really transparent in meaning. /siːl/ does exist in a handful of other English words, such as conceal. So you could make the argument that it is slightly more transparent than statistics. This illustrates that all concepts discussed here are matters of degree. building and interesting are both more transparent in meaning and analyzable. You might still want to treat them separately if you look into -ing as derivational suffix because they are strongly lexicalized. That means they are unlikely to be perceived compositionally, i.e. we have them stored as a whole in our lexicon and there is little to no analogical derivation happening.
Finally, morphemes vary in terms of and how widely they are spread across the lexicon and how commonly they are used to derive new words. A highly productive derivational affix is used with a large variety of roots. This is true of the regular inflectional affixes in English. -s is used as plural suffix on most nouns and it is also the most likely candidate for a neologism. An irregular plural like -en in oxen is more like a living fossil. It is limited to certain words and never used with new vocabulary.
In derivation, productivity is not as clear cut.
Let’s consider the adjectival suffix -ish as in the examples below, taken from the Corpus of Contemporary American English (COCA) with the query [word = ".+-ish"].
- I’m still feeling flu-ish.
- … for a nation that was a loyal-ish member of NATO.
- That was selfish rather than other-ish.
In modern spoken language these types of derivations feel quite common. They may not be considered standard or formal language, which is why you will often find them hivenated. Still, intuitively, -ish should be considered productive.
Let’s try to catch more -ish adjectives with a more general query.
It is a good idea to exclude capital letters with [^A-Z] since a homonym of -ish frequently occurs with nationalities/language names: [word = "[^A-Z].+ish" & class = "ADJ"].
Let’s also look at some other suffixes used to derive adjectives and compare some numbers from the BNC with some minimal cleanup:
| tokens | suffix | cqp query (BNC) |
|---|---|---|
| 8196 | -ish | [word = "[^A-Z].+ish" & class = "ADJ"] |
| 168294 | -ous | [word = ".{2,}ous" & class = "ADJ"] |
| 1025618 | -al | [word = ".{2,}al" & class = "ADJ" & word != "real"%c] |
barplot(c(8196, 168294, 1025618),
ylab = "token frequency",
names.arg = c("-ish", "-ous", "-al"))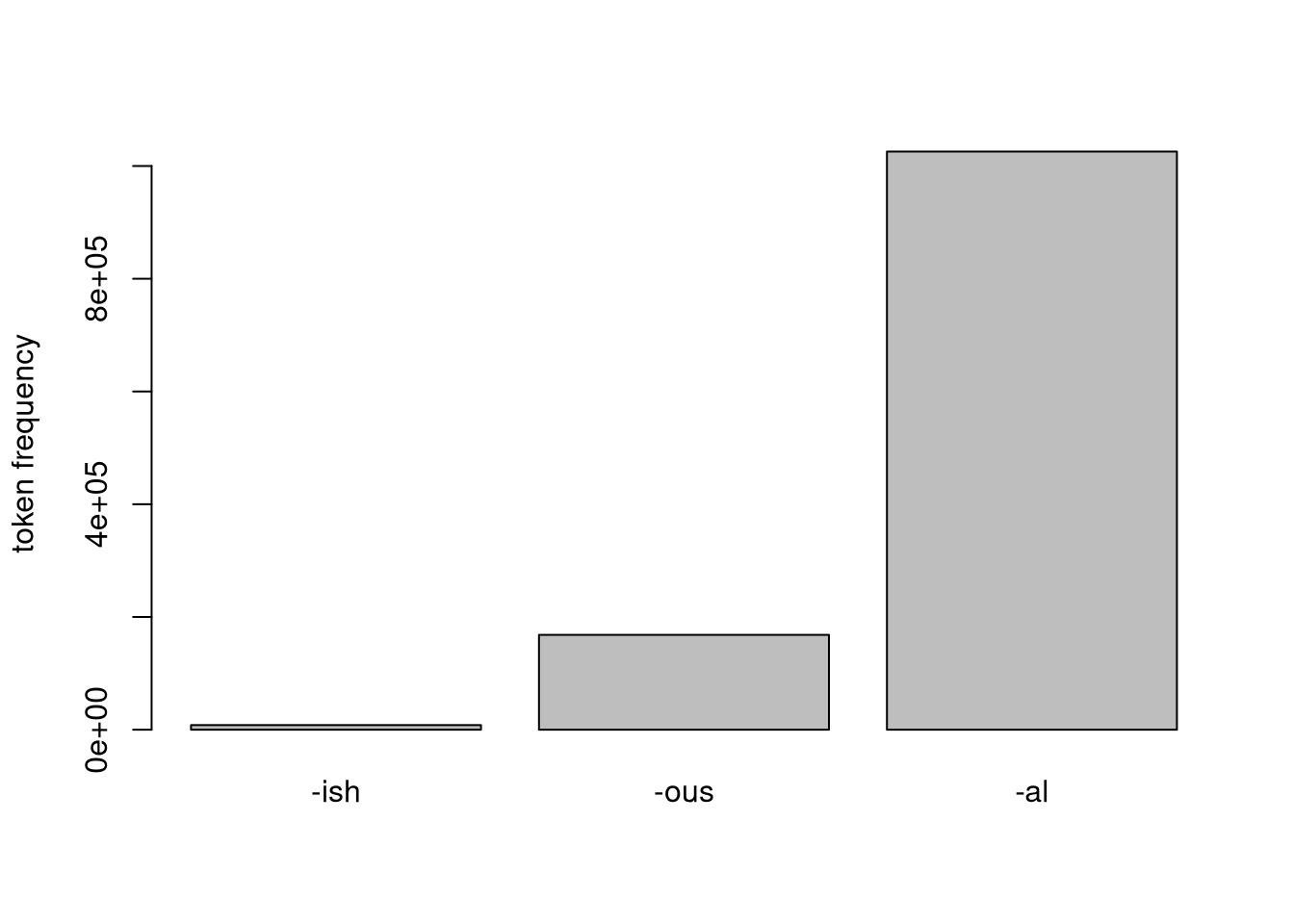
On a first glance, -ish is much less frequent in the BNC.
This could have something to do with the composition of the corpus (try to restrict to match.text_mode = “spoken.” Is there a difference?).
Normalizing relative to sample size does not help in this case because our sample is the same across.
We could also look for disproportional amounts of false positives due to our queries, but maybe this is not going to be necessary.
Frequency alone is not a sufficient measure for productivity.
We need to check how much of the vocabulary is covered as well.
One measure that can be used is the type-token ratio.
How many occurrences are there relative to how many different words they occur across?
We can get the type frequency by creating a frequency list with count and counting how many lines it has.
A quick way to do this is to use an external command line tool called wc with the -l option for line count: count by word %c > "| wc -l".
Note: the following graphs were made with the statistical software called R. I provided the code just in case anyone is interested.
| types | tokens | suffix |
|---|---|---|
| 557 | 8196 | -ish |
| 1410 | 168294 | -ous |
| 6315 | 1025618 | -al |
barplot(c(557, 1410, 6315),
ylab = "type frequency",
names.arg = c("-ish", "-ous", "-al"))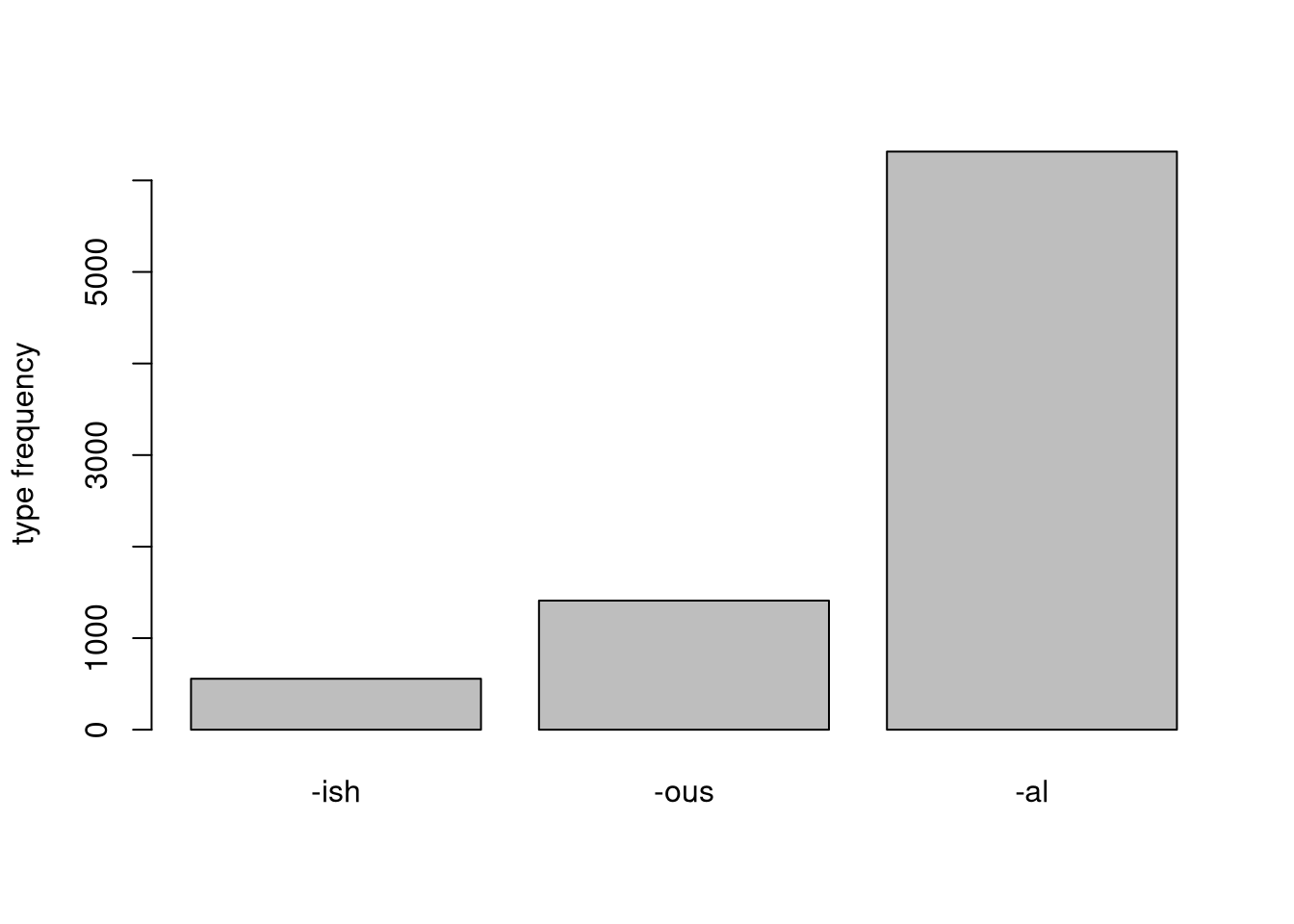
The discrepency in type counts is already much lower and when we take the ratio, we can see that all of a sudden -ish is far ahead. It might not be as frequent as the other two suffixes, but it is also relatively more evenly spread over different roots. You could also imagine the other suffixes being bound to fewer roots that are very high in frequency individually.
barplot(c(557, 1410, 6315) / c(8196, 168294, 1025618),
ylab = "type-token ratio",
names.arg = c("-ish", "-ous", "-al"))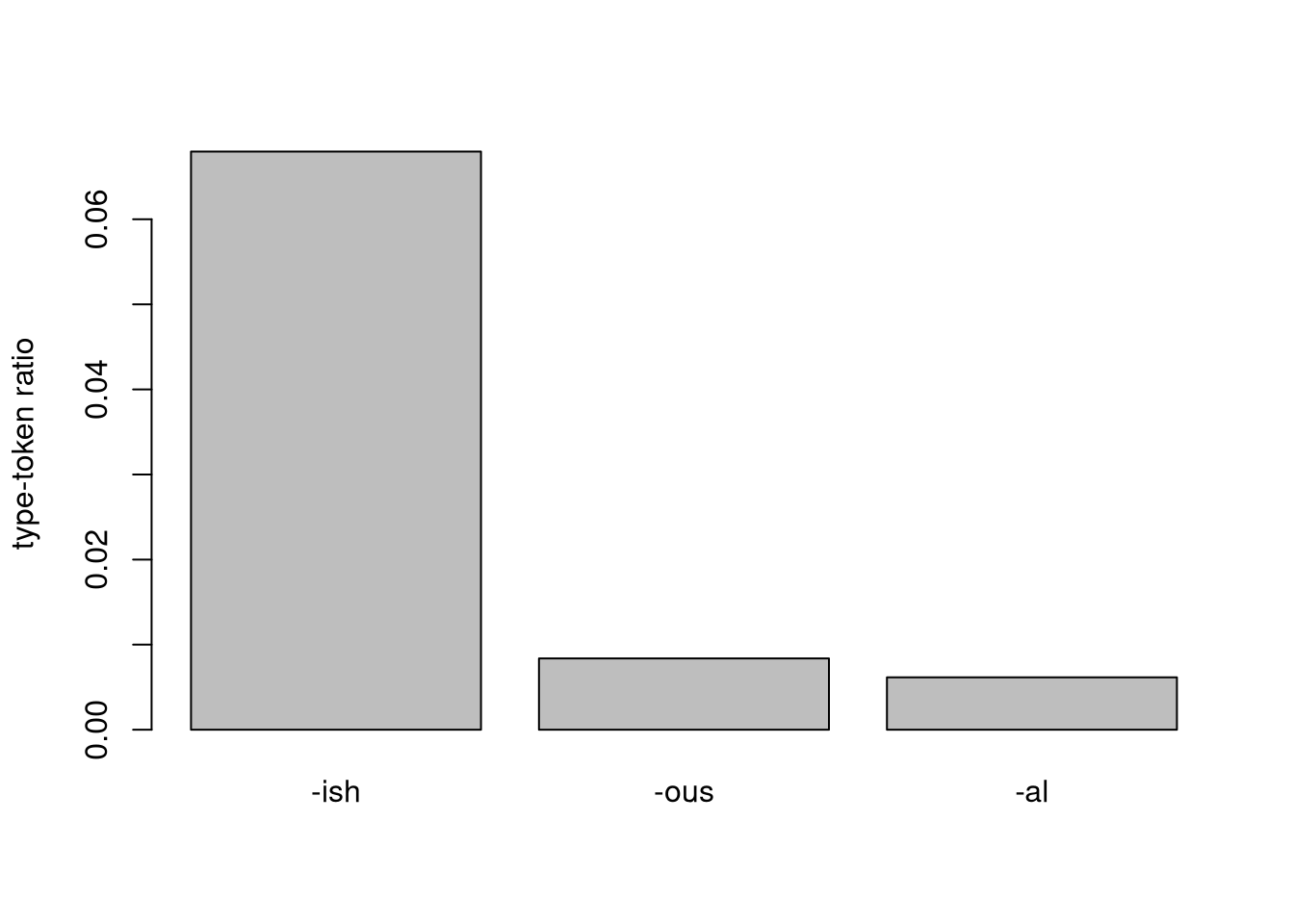
An even better measure is the hapax-token ratio.
Instead of measuring the spread over different roots, we can measure the amounts of roots that only occur once.
This may serve as an indicator for the formation of neologism.
To get hapax frequency, we can add the following to our queries: [... & f(word) = 1].
We can observe the following result:
| hapaxes: | types: | tokens: | suffix |
|---|---|---|---|
| 271 | 557 | 8196 | -ish |
| 584 | 168294 | -ous | |
| 3438 | 1025618 | -al |
barplot(c(271, 584, 3438) / c(8196, 168294, 1025618),
ylab = "hapax-token ratio",
names.arg = c("-ish", "-ous", "-al"))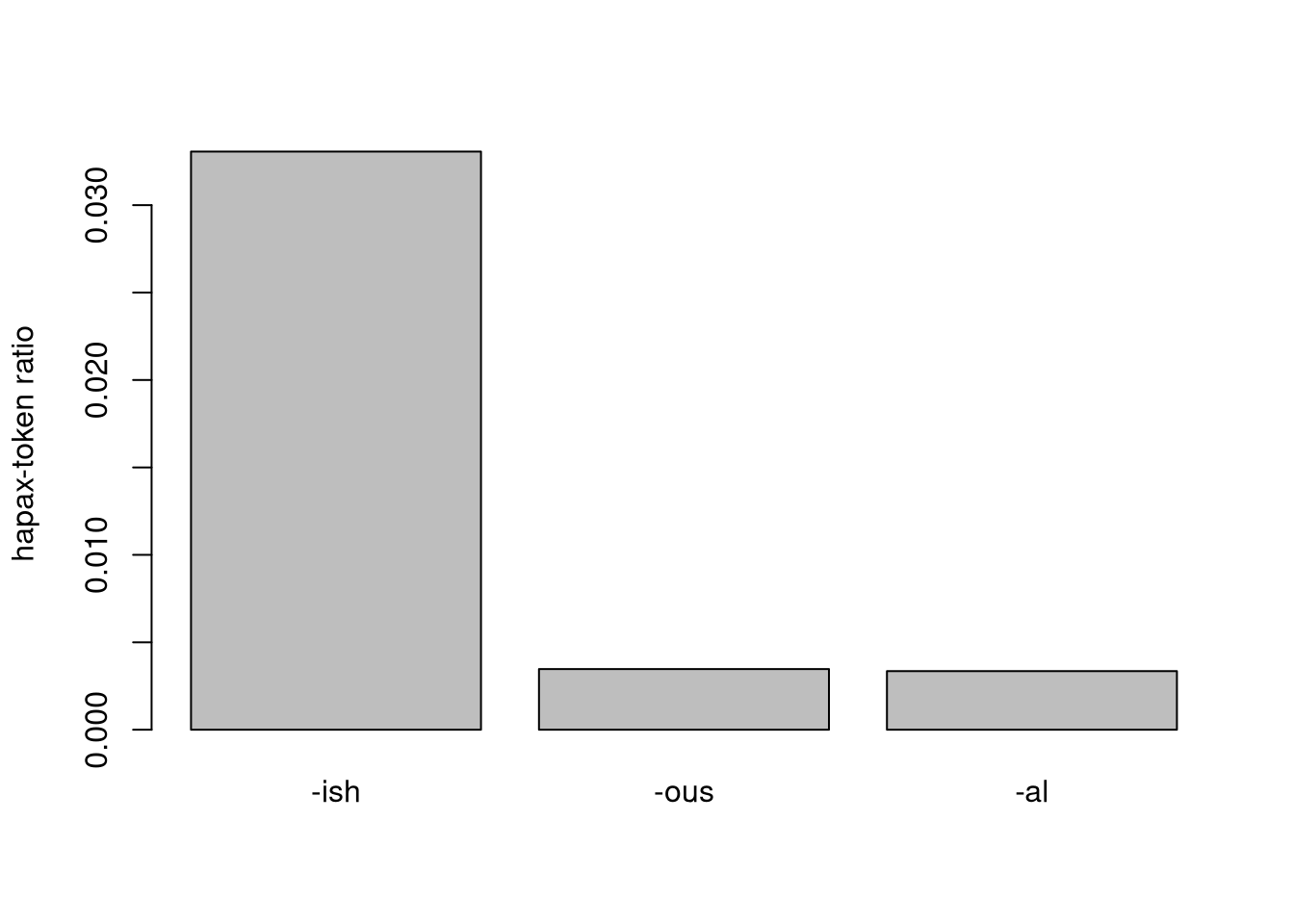
Even though -ish is comparatively infrequent, it occurs with a lot of types and seems to be used to form neologisms more often than the other two. This might indicate that it is more productive, and also that it is a more recent phenomenon because none of the uses have had the chance yet to become frequent individually. Another observation we can make is that while -al’s type-token ratio is higher than that of -ous, the hapax-token ratios are almost even. The data suggests that their productivity is similar, but that -al is more wide-spread in the lexicon, which makes intuitive sense.